In this dialog window (click the button shown in Fig. 1.9), the user sets criteria for
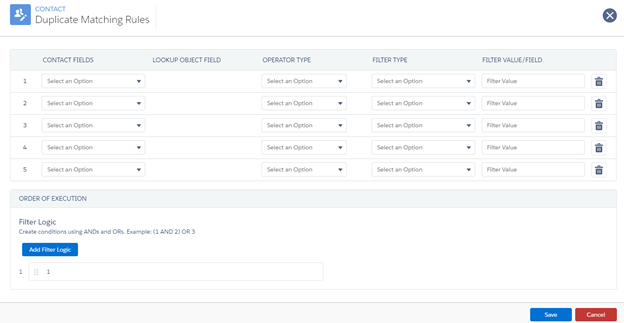
identifying duplicate records. The configuration process is the same for whichever object the criteria is set on. The only difference is that the available fields to match on depend on the object. When identifying duplicates for any object except the Contact, if there are multiple duplicates, the oldest record is used. When identifying duplicates for the Contact, if more than one match is found, they will be shown on the Duplicate Review Screen after importing. If only one Contact match is found, that can be configured to automatically update by checking “Automatically Update Duplicates” on the Data Source record. Figure 1. 1.13a — The default screen for setting duplicate criteria
[Object] Fields: A list of all fields on the object available for matching
Lookup Object Field: If the initial field chosen is a lookup, choose the field on the related record to match
Operator Type: The operator used in comparison between the object value Filter Value/Field
Filter Type: Field allows the user to choose a Big Table field. Value allows the user to set a static value
Trash Icon: Deletes the entire row
Order of Execution and Filter Logic (bottom of dialog): Use “AND” and “OR” to set the logic for evaluating the criteria. Multiple Rows of filter logic can be added, in which case they are evaluated in sequence, with 1 being the highest priority. Once a match is found, the evaluation stops.
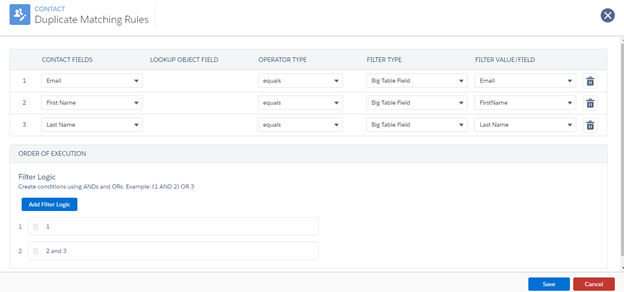
With the configuration shown in Fig 1.13b (below), email match is the highest priority and the Import Process will first search for Contacts with matching email address and update them if found. If there is no contact with a matching email address, the process will then search for contacts with matching first and last names; if none is found, then a new Contact will be created. Figure 2. 1.13b — Multiple criteria with sequential matching
Feedback Widget
Was this page helpful?
Thanks — comments are optional, but we’d love to hear what was helpful.